

NVIDIA DGX A100
AI 基础架构的通用系统
NVIDIA DGX A100
全球首款基于 NVIDIA A100 构建的 AI 系统
NVIDIA DGX™ A100 是适用于所有 AI 工作负载的通用系统,为全球首款 5 petaFLOPS AI 系统提供超高的计算密度、性能和灵活性。NVIDIA DGX A100 采用全球超强大的加速器 NVIDIA A100 Tensor Core GPU,可让企业将深度学习训练、推理和分析整合至一个易于部署的统一 AI 基础架构中,该基础架构具备直接联系 NVIDIA AI 专家的功能。
观看视频 下载性能数据表AI 数据中心的基本组成部分
各种 AI 工作负载的通用系统
NVIDIA DGX A100 是适用于所有 AI 基础架构(包括分析、训练、推理基础架构)的通用系统。该系统设定了新的计算密度标杆,将 5 petaFLOPS 的 AI 性能装进 6U 尺寸,用一个平台代替所有 AI 工作负载的传统基础架构孤岛。
DGXperts:集中获取 AI 专业知识
NVIDIA DGXperts 是一个拥有 14000 多位 AI 专业人士的全球团队,这些团队成员在过去十年间积累了丰富的经验,能够帮助您更大限度地提升 DGX 投资价值。
更快的加速体验
NVIDIA DGX A100 是在全球率先采用 NVIDIA A100 Tensor Core GPU 的系统。通过集成八块 A100 GPU,此系统可出色完成加速任务,并可针对 NVIDIA CUDA-X™ 软件和整套端到端 NVIDIA 数据中心解决方案进行全面优化。
卓越的数据中心可扩展性
NVIDIA DGX A100 内置 Mellanox ConnectX-6 VPI HDR InfiniBand 和以太网适配器,其双向带宽峰值为 450Gb/s。此优势是使 DGX A100 成为 NVIDIA DGX SuperPOD™ 等大型 AI 集群基础构件的诸多因素之一,也是成为可扩展 AI 基础架构企业蓝图的原因之一
一个更简单快捷的解决人工智能的方法
NVIDIA AI 初学者工具包为您的团队提供所需的一切,从世界级的 AI 平台,到优化的软件和工具,再到咨询服务,让您的人工智能计划快速启动并运行。无需浪费时间和金钱建立人工智能平台。在一天内接通电源,在一周内确定用例,并更快地开始生产模型。
了解详情适用于开发者

快速解决更庞大、更复杂的数据科学问题
优势
- 采用经过优化的即用型 AI 软件,无需进行繁琐设置和测试。
- 以卓越性能加快迭代速度,更快提供更优质的模型。
- 避免在系统集成和软件工程上浪费时间。
适用于 IT 经理

大规模部署基础架构并实现 AI 的运营
优势
- 一个系统适用于所有 AI 工作负载,带您体验精简基础架构设计和产能规划。
- 以最小的占用空间实现最高的计算密度和性能。
- 从容器到芯片,每一层都充分利用内置安全机制。
适用于企业领袖

缩短分析时间,提升 AI 投资回报率
优势
- 提高数据科学家的工作效率,消除非增值工作。
- 缩短从概念到生产阶段的开发周期。
- 根据 DGXperts 提供的建议扫清障碍。
划时代的性能
训练
DLRM 训练
在大型模型上将 AI
训练吞吐量提升高达 3 倍

HugeCTR 框架上的 DLRM,精度 = FP16 | 1x DGX A100 640GB 批量大小 = 48 | 2x DGX A100 320GB 批量大小 = 32 | 1x DGX-2 (16x V100 32GB) 批量大小 = 32。归一化为 GPU 数量的加速性能。
推理
RNN-T 推理:单流
AI 推理吞吐量提升高达
1.25 倍
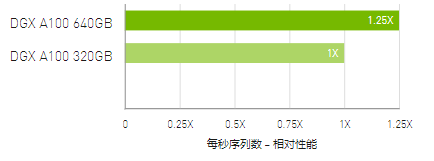
使用 (1/7) MIG 分片测量 MLPerf 0.7 RNN-T。框架:TensorRT 7.2,数据集 = LibriSpeech,精度 = FP16。
数据分析
大数据分析基准测试
吞吐量比 CPU 提升高达 83 倍,比 DGX A100 320GB
提升高达两倍

大数据分析基准测试 | 在 10TB 数据集上运行 30 次分析零售查询、ETL、ML、NLP | CPU:19x 英特尔至强金牌 6252 2.10 GHz,Hadoop | 16x DGX-1(每个 8x V100 32GB),RAPIDS/Dask | 12x DGX A100 320GB 和 6x DGX A100 640GB,RAPIDS/Dask/BlazingSQL。归一化为 GPU 数量的加速性能

探索功能强大的 DGX A100 组件
1八块 NVIDIA A100 GPU,GPU 总显存高达 320 GB
每块 GPU 支持 12 个 NVLink 连接, GPU 至 GPU 带宽高达 600 GB/s
2、六个第二代 NVSWITCH
双向带宽高达 4.8 TB/s, 比上一代产品高出 2 倍
3、九个 Mellanox ConnectX-6 VPI HDR InfiniBand/200 Gb 以太网
双向带宽峰值高达 450 GB/s
4、两块 64 核 AMD CPU 和 1 TB 系统内存
以 3.2 倍核心数量满足超密集的 AI 作业
5、15 TB 第四代 NVME SSD
带宽峰值高达 25 GB/s,比三代 NVME SSD 快两倍
NVIDIA DGX A100 技术特性

NVIDIA A100 Tensor Core GPU
NVIDIA A100 Tensor Core GPU 可针对 AI、数据分析和高性能计算 (HPC) 实现出色的加速,应对极其严峻的计算挑战。借助第三代 NVIDIA Tensor Core 提供的巨大性能提升,A100 GPU 可高效扩展至数千块,或在使用多实例 GPU 时,可将其分配为七个较小的专用实例对各种规模工作负载进行加速。
了解详情
多实例 GPU (MIG)
借助 MIG,可将 DGX A100 中的八块 A100 GPU 配置为多达 56 个 GPU 实例,每个实例都具有自己的高带宽内存,高速缓存和计算核心,完全隔离。这使管理员可合理调配 GPU 资源,确保多个工作负载的服务质量。
了解更多
NVLink 和 NVSwitch
DGX A100 中的第三代 NVIDIA® NVLink® 使 GPU 至 GPU 直接带宽提高一倍,达到600 GB/s,几乎比 PCIe 4.0 高出 10 倍。DGX A100 还采用新一代 NVIDIA NVSwitch™,其速度是前一代的两倍。
了解更多
Mellanox ConnectX-6 VPI HDR InfiniBand
DGX A100 采用最新 Mellanox ConnectX-6 VPI HDR InfiniBand/以太网适配器,每个适配器的运行速度高达200 Gb/s,为大规模 AI 工作负载创建高速网络结构。

优化的软件堆栈
DGX A100 集成经过测试和优化的 DGX 软件堆栈,包括通过 AI 调整的基本操作系统、所有必需的系统软件以及 GPU 加速应用、预训练的模型以及 NGC™ 提供的更多功能。
了解更多
内置安全机制
DGX A100 采用多层方法为 AI 部署提供了最强大的安全性,该方法可以保护所有主要的硬件和软件组件,包括自加密驱动、签名软件容器、安全管理和监控等。
了解 NVIDIA DGX 系统的企业级支持
了解更多